


首页财产ai正文 FARS杀疯了 春节时期,AI科学家FARS持续公然运行228小时,天生244个假定,产出100篇短论文。 2026-02-25 07:20 ·呆板之心存眷AI的 编纂 Sia AI投资人解读· FARS能7×24小时不变运行,228小时天生244个假定、产出100篇短论文,平均每一篇论文成本约1000美元。经评审,论文平均患上分为5.05,高在人类投稿平均分。 · 今朝FARS处在“算力换智能”阶段,效率开消高,间隔年夜范围低成本运行还有有空间。 总结:FARS展示了主动化科研流水线的可行性与潜力,产出论文质量较高,但于效率及成本节制上有晋升空间,值患上存眷其将来成长。内容由AI天生,仅供参考
这个春节,AI圈最硬核的一场「真人秀」,悄然完成为了阶段性收官。
主角不是动漫人物,也不是舞枪搞棒的呆板人,而是一名7×24小时从不倦怠的AI科学家FARS(Fully Automated Research System)。
这套由Anale妹妹a(日行踪)打造的全主动研究体系,于长达228小时28分33秒的持续公然运行中,本身提假定、做试验、写论文,共天生244个研究假定,「肝」出100篇短论文(short paper)。
算下来,于这座流水线式的「科研工场」中,每一隔约2小时就有一篇论文产出。

让AI本身写100篇论文方针告竣,花了228个小时。今朝,规划连续一个月的直播仍于举行中。直播地址:https://anale妹妹a.ai/fars
这类跳出传统科研范式的工业级吞吐量,很快让围不雅网友坐不住了。
首批深度「验货」的专业网友给出了一个颇为一致的判定:成果跨越预期、相称精彩。
假如把它看成人类顶会论文,还有不敷冷艳;但若思量到这是一个全主动体系的阶段性产出,其完成度已经经较着凌驾许多人的事先预期。
「思量到这只是一个AI的自立起步,能7×24小时不变产出到这个质量,还有要啥自行车?」


并且,真work没有通篇幻觉。
至少于当前阶段,FARS已经经完成为了一次要害超过。它初次证实,一条无人值守的科研「流水线」不仅能跑,并且能于相对于不变前提下,连续产出具有必然学术竞争力的short paper级事情。
「发论文这件事自己的稀缺性」被捣毁了。
可骇的「工业节奏」,算力正于转化为常识
FARS其实不是一个单体模子,而是一套多智能系统统,包括四个功效模块:
Ideation(构想):卖力文献调研与假定天生
Planning(计划):卖力试验方案设计
Experiment(试验):卖力代码编写与履行
Writing(写作):卖力论文撰写
从及时运行界面可以直不雅看到,FARS以项目行列步队的方式并行推进多个研究使命。每一个课题依次穿过Ideation → Planning → Experiment → Writing四个阶段,流程高度模块化,出现出较着的「科研装置线」特性。
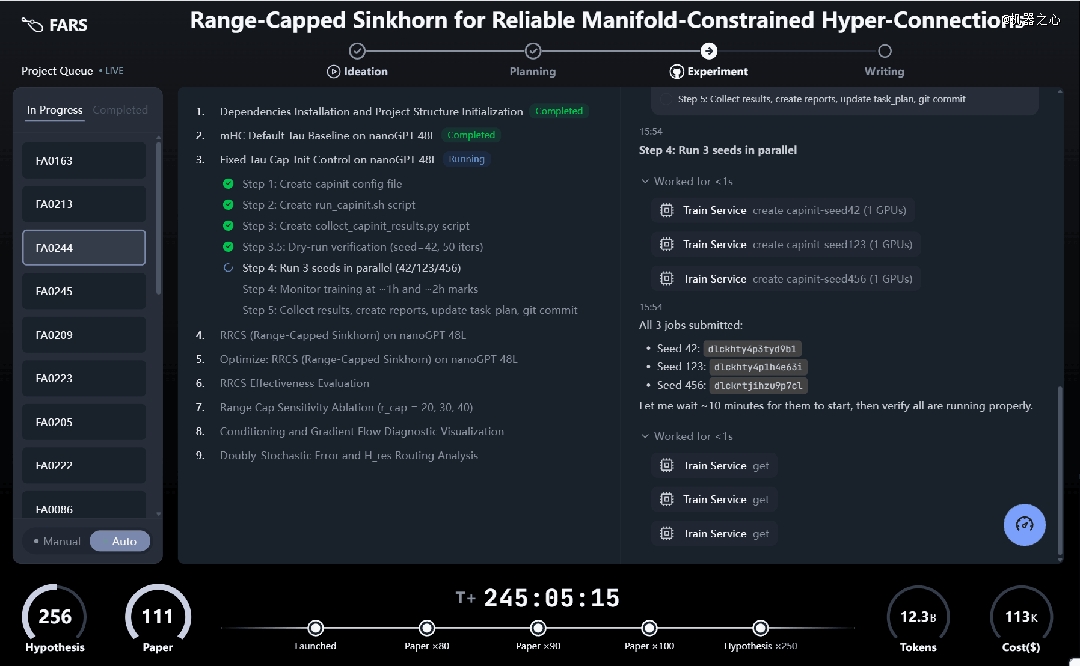
FARS及时运行界面:从假定天生到论文写作,主动化科研流水线初次以可不雅测形态完备睁开。
为了让它心无旁骛的做研究,Anale妹妹a(日行踪)还有给它搭建了一个160张显卡的计较集群,并答应它挪用险些任何开源及闭源年夜模子,试验前提远超年夜部门高校试验室。
而这条「流水线」的产能,已经经到了让人很难轻忽的水平。于约228小时(≈9.5天)的持续运行周期内:
体系天生244个研究假定
完成100篇short paper
累计耗损114亿Token
总成本约10.4万美元(≈75万元人平易近币)
全程无人干涉干与。
进一步归一化后,这套体系的「工业节奏」变患上越发直不雅:平均每一隔约2小时17分就有一篇研究论文完成,平均每一篇论文成本约莫1000美元,破费1亿多Token。
对于比人类科研常见的3–6个月/篇的周期,这类吞吐差距险些是数目级级另外,成本也极其低廉。
不外,假如把眼光从吞吐转向效率,约1.14亿Token /篇的耗损,已经经较着高在平凡写作天生(凡是百万级 Token )以和常见繁杂Agent使命(凡是百万、万万级Token)的开消。
这注解,FARS仍处在「算力换智能」的阶段,其体现更多来自计较密度,而非算法效率的极限压缩。
综合来看, 一方面,FARS已经经用实测成果证实,端到端主动化科研流水线于吞吐层面是切实可行的。另外一方面,其当前的Token与成本布局,间隔「充足自制地年夜范围跑」还有有工程空间。
质量:它写患上快,那写患上好吗?
量年夜,从来不主动等在质优。FARS写出来的工具,到底处于甚么程度?
为此,研究团队利用斯坦福年夜学开发的AI审稿体系Agentic Reviewer(paperreview.ai),根据ICLR的评审尺度,对于这100篇论文举行了同一打分。
按照开发者公然评估,Agentic Reviewer于审稿一致性上,已经到达人类审稿人的判定程度。
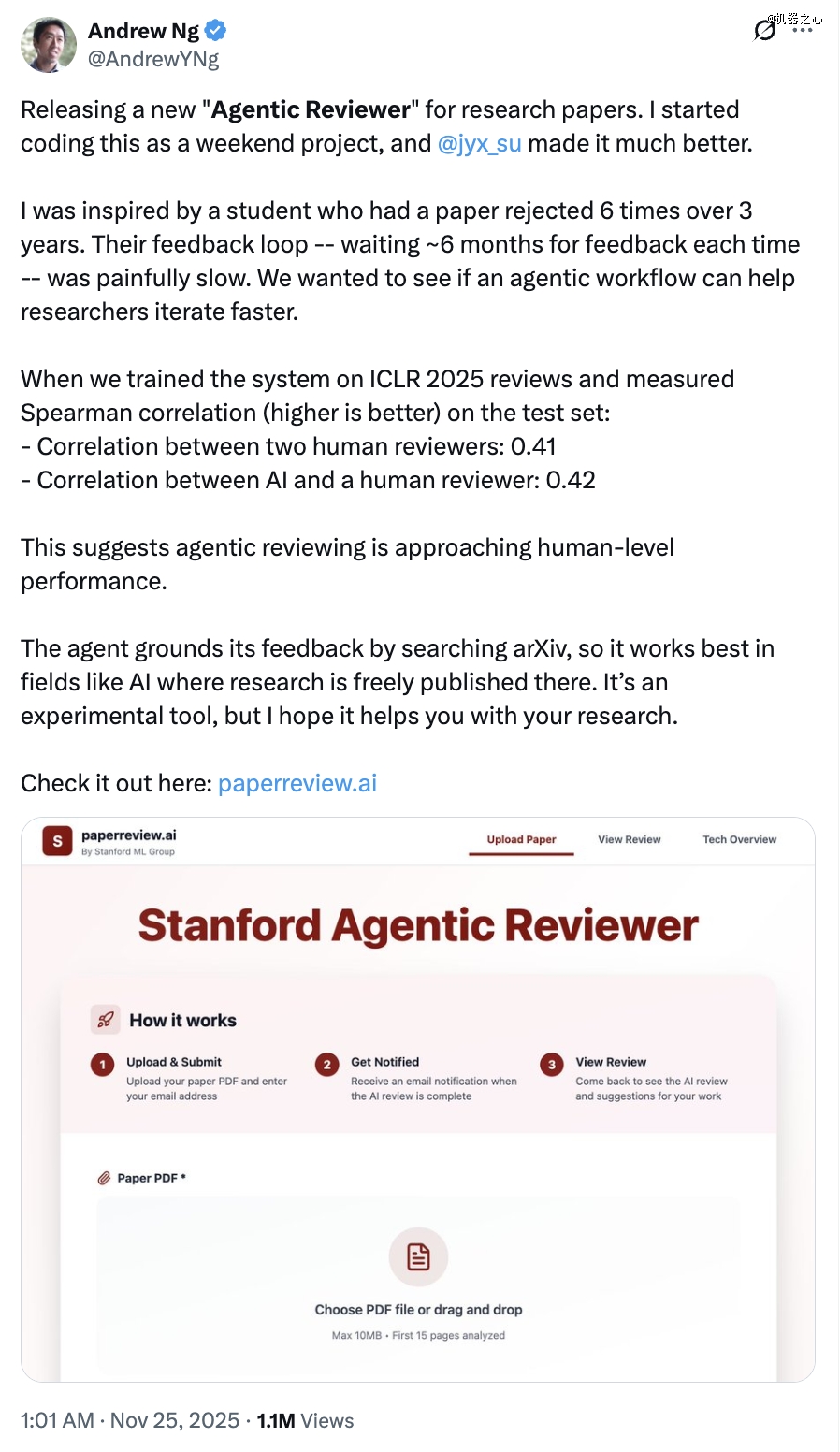
开发者于ICLR 2025审稿数据 上做了对于比评测,利用的是Spearman相干系数。人类vs人类:0.41;AI vs人类:0.42。开发者认为agentic reviewing正于迫近人类程度。
从总体评分成果来看,FARS产出的100篇论文中,平均患上分为5.05(区间3.0–6.3)。
极少量论文处在3.0–4.5的低分段,也有少少数冲破6.0分。
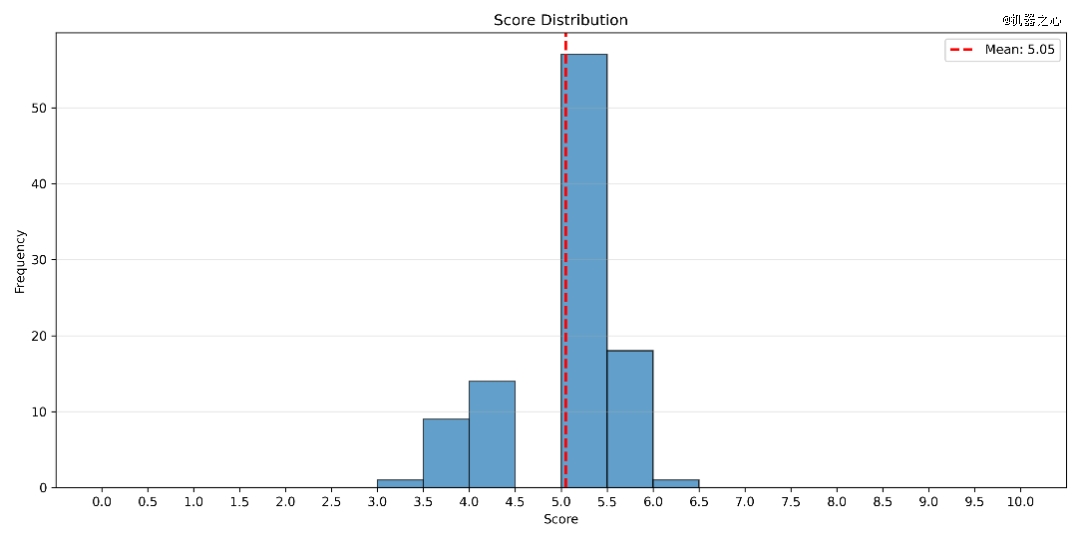
FARS论文分数重要堆于5分四周,申明产出质量其实不是随机颠簸,而是已经经形成相对于不变的「质量带」。极少量样本进入6分以上区间,象征着体系偶然能产出*作品。
这个成就,与人类战绩比拟,又怎样呢?
作为参照,ICLR 2026人类投稿的平均分为4.21,而终极被吸收论文的平均分为5.39。
比照来看,FARS的平均分5.05,已经经较着高在人类投稿的总体平均程度,但间隔「平均中稿线」仍存于差距。
堪称比下有余,比上未满。
FARS天生的学术论文平均分跨越人类投稿者的平均程度,但与平均中稿分数仍有差距。
需要再次夸大的是,本次主动化出产以短论文为主,并未以当前学术集会的评审尺度作为优化方针。是以,不管是斯坦福年夜学Agentic Reviewer 还有是其他基在现有特定审稿尺度的 AI 审稿成果,都只能作为一种参照,而非盖棺定论。
据团队吐露,除了AI审稿外,今朝也于同步开展人工质量评审,并将于评估完成后形成综合质量陈诉。
即便于这一谨慎条件下,将先后两部门数据归并不雅察,总体旌旗灯号仍旧较为清楚:于靠近人类评审标准的评价系统中,FARS已经然一台不变的中分段输出呆板。
论文深读:
从「极速跟进」到「直面掉败」
假如说前面的数据与评分只能给出一条宏不雅刻度,那末详细论文样本,才真正袒露出FARS的研究成色。
已经有网友拆解此中一篇LLM-as-a-Judge事情后评价,这种论文于择要构造与问题切入上已经经相称工致。
思量这是AI主动产出,完成度已经经「凌驾预期」。框架图、成果图、阐发基本都齐备,「像那末回事」
也有人感觉编号为FA0008 的项目「make sense」。
接下来,咱们选择一成一败两篇代表作,一探毕竟。
先看「做成」的一篇FA0042。它对准的是文本embedding里一个老抵牾:
双向留意力质量高,但会粉碎KV-cache;因果留意力能流式推理,但暗示能力亏损。

FA0042的解法很是工程导向——练习阶段用双向拿质量,推理阶段用因果保效率。详细路径是先训一个双向teacher,再把能力蒸馏进causal student。为了不直接切双向带来的漫衍漂移,论文还有引入了刚发布不久的GG-SM做渐进过渡。
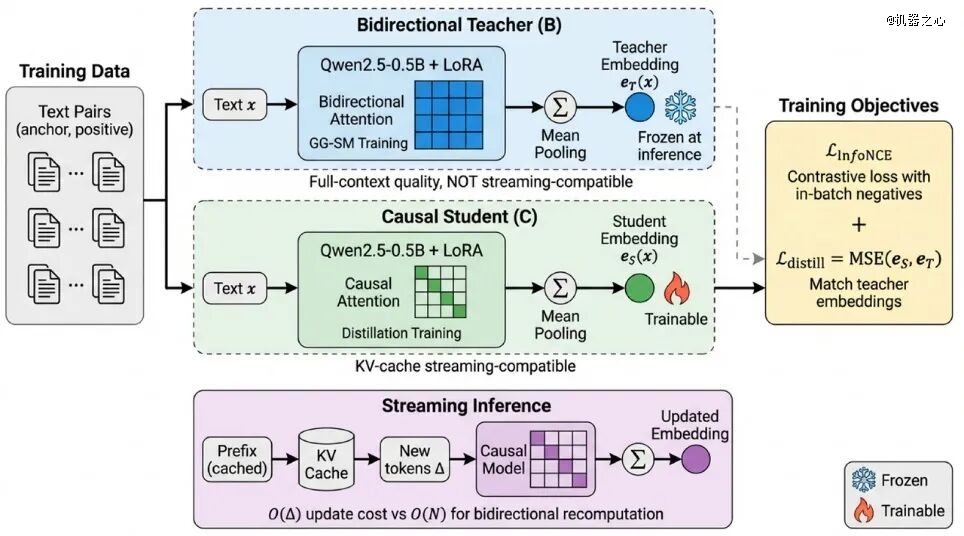
成果也确凿「能打」, 这条工程折衷线路被验证是work的。

MTEB-slice重要成果
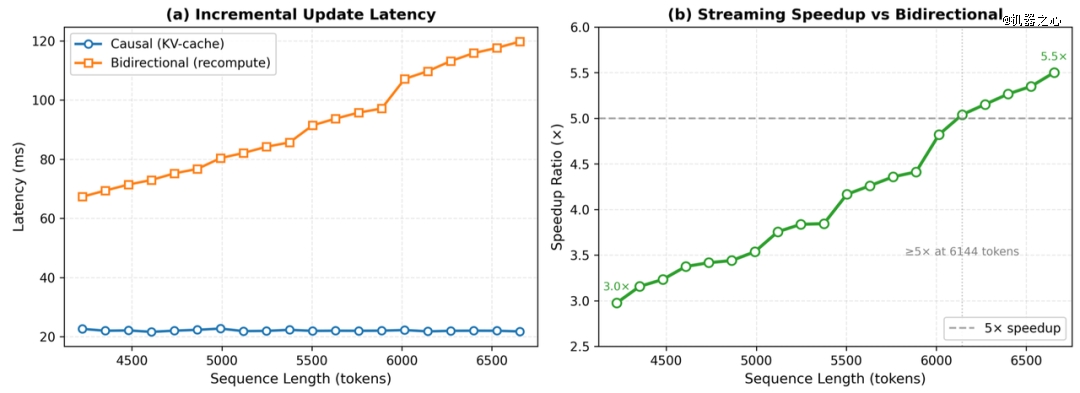
流式推理延迟对于比
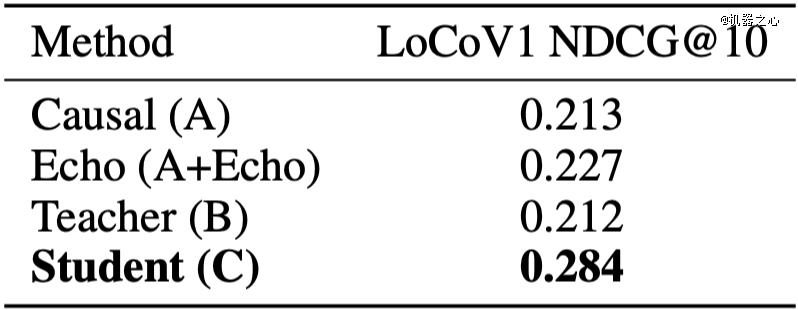
LoCoV1长文档检索成果。student模子以0.284的NDCG@10年夜幅*所有baseline(包括teacher的0.212),出人意表。
固然,short paper气质也很足:细粒度成对于使命晋升有限,长文档检索反超teacher的机制还有没彻底讲透。
但更值患上留意的是,蚂蚁集团的GG-SM发布3天就被接入试验流程,这类紧跟前沿的速率,自己就是FARS体系灵敏性的一个旌旗灯号。
再看一篇「没做成」的FA0121。
它的文献调研很给力,盯上了DeepSeek新提出的Engram稀少架构,并抓到了一个很研究味的问题——
hot-to-cold advantage flip ,即Engram中的门控(gate)于练习历程中难以正确按照n-gram embedding的现实效用举行调解,存于高频(hot)及低频(cold)偏置。

为了打破这类「马太效应」,FARS测验考试了一个直觉上很是硬核的方案:试图经由过程「反事实门控监视(CGS)」修复DeepSeek Engram架构中的「冷热偏置」问题。
于特定练习步调中别离强迫gate全开及全关,计较两种环境下的loss差值来预计当前n-gram embedding的现实效用,以此作为辅助监视旌旗灯号来练习gate。
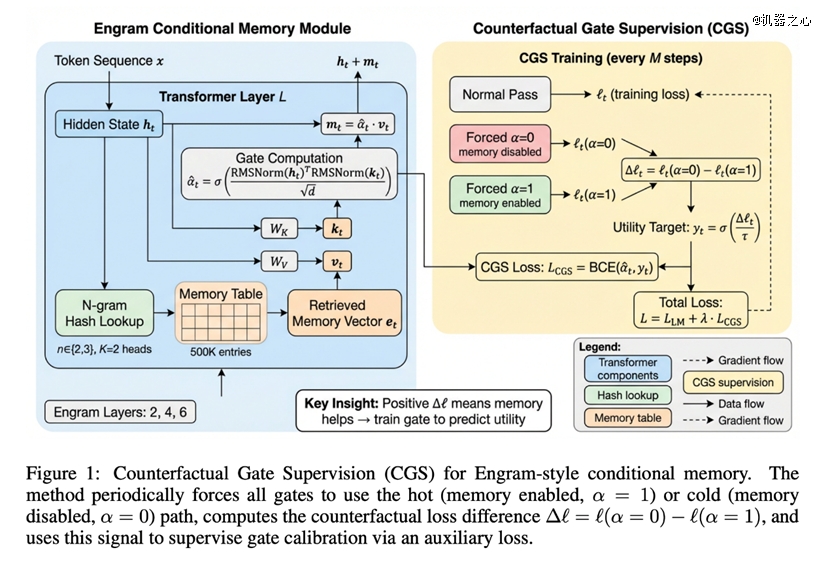
FA0121要领示用意

主试验成果
思绪很直觉。但成果很老实——基本没救回来。
CGS带来的那点晋升,甚至不如让模子多练习几步来患上其实。这申明,要解决AI的成见,光靠「锻练现场打分」是不敷的,患上从更深层的轨制(架构)上下功夫。
论文给出的复盘也很到位:Gate及n-gram embedding的练习是一个彼此耦合的体系动力学问题,不是简朴加监视就能补的。
这篇事情的价值正于在:它没有试图袒护负面成果,没有为了寻求正面成果而窜改数据或者强行注释,而是经由过程一套周密的诊断性试验(Diagnostic Experiments),反思CGS的掉败。
这类「算法老实」是当前学术界稀缺的品质。

舆论场:
从「又一个Demo」到「科研流水线雏形」
跟着FARS「直播真人秀」数据披露,社区会商也迅速升温,高频指向一个要害词——出产线。
不少围不雅者很快捉住了真实的打击点:此次激发不安的,其实不是某一篇论文写患上多冷艳,而是体系所揭示出的持续科研运转能力。
当一个体系可以或许不变提出假定、主动完成试验、并连续吐出成稿时,评价坐标实在已经经悄然挪动。问题再也不是「AI会不会写论文」,而是更具布局性的那一句—— AI是否最先具有科研工业产能的雏形。
这类叙事重心的变化,自己就象征着社区对于AI科研体系的预期正于抬升。一些技能会商甚至认为,LLM于AI标的目的论文写作上的能力已经「基本够用」,残剩差距更多表现于工程细节层面。
「3个月内就可能呈现很是成熟可用的主动paper pipeline。」
换言之,年夜大都人险些已经经默许:科研流水线时代,早晚会来。真正悬而未决的问题反而是,当科研最先范围化主动出产,人类的不成替换性毕竟还有剩下甚么?
对于此,也有人给出谜底:决议上限的,也许仍是研究者小我私家咀嚼。

固然,社区并不是只有单一声音。
有人认为,与其存眷纯真scale出年夜量「平凡conference paper」,不如将算力与模子能力投入到真正坚苦的开放问题上,这也许才是更具持久价值的标的目的。
无穷心智的出发点
FARS的这100篇论文,其实不是尽头,更像是一枚被钉下的坐标点。
它证实了一件很主要的事:端到端主动科研流水线,已经经可以或许于相对于不变的运行前提下,连续产出具有必然学术竞争力的short paper,而且最先揭示出基础的自我纠错与负成果陈诉能力。
这象征着,主动化科研*次以一种可持续运转的体系形态,正式进入实际。
但若把放年夜镜再压近一层,当前阶段的天花板一样清楚可见。
FARS很会把一条合理路径走通,却还有不敷擅长于繁杂假定空间中做出真正具备冲破性的研究弃取;能完成布局完备的论证,但于思惟压强及机制洞察上仍有晋升空间;而于算力使用率上,体系也还有逗留于较着的「算力换智能」阶段。
现在的FARS,更像一名极端勤劳、练习有素且从不倦怠的低级研究员,间隔那种可以或许不变打召盘会级事情的成熟研究者,仍有一段需要超过的进化间隔。
不外,真正主要的也许其实不是它现在已经经多强,而是那条「无穷心智出产线」,已经经可以不变地跑起来。
【本文由投资界互助伙伴呆板之心授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-雷火·竞技